Tipos de modelos OLAP. Tabular o Multidimensional?
En la entrada anterior establecimos la diferencia entre OLTP y OLAP, y en esta ocasión vamos a hacer los propio desglosando los tipos que podemos encontrar dentro del modelo OLAP.
Los modelos OLAP tienen como principal característica que cumplir FASMI (Fast Analysis of Shared Multidimensional Information) y en este orden:
- Fast: el sistema tiene que entregar la mayor cantidad de datos en el menor tiempo posible en aproximadamente 5 segundos. Para el análisis básico y elemental, no debe tardar más de 1 segundo y pocas veces puede llegar a ascender a 20 segundos.
- Analysis: lógica de negocio relevante y análisis de información que se simple para los analistas de negocio no expertos.
- Shared: poder gestionar múltiples actualizaciones de forma segura y rápida.
- Multidimensional: requisito básico, el sistema resultado debe proporcionar una vista conceptual multidimensional de los datos, es decir, podemos combinar dimensiones para obtener el resultado (valor) buscado.
- Information: el sistema debe contener todos los datos necesarios para las aplicaciones.
Modelo Multidimensional
Dentro del Modelo Multidimensional hay que diferenciar entre diferentes tipos en función de la arquitectura de almacenamiento por:
ROLAP (Relational Online Analytical Processing). Almacena las agregaciones en datos relacionales indexados junto con los datos origen. No utiliza almacenamiento multidimensional, por lo que los datos ROLAP son más lentos para consultar y procesar que MOLAP o HOLAP, pero permite el acceso en tiempo real (Direct Query) a los datos y utiliza menos espacio de almacenamiento. Con esta arquitectura no necesitaríamos procesar/implementar de nuevo el proyecto de SSAS. ROLAP podría crear vistas indexadas para el acceso a la información.
MOLAP (Multidimensional Online Analytical Processing). MOLAP es el modo de almacenamiento más utilizado. Almacena tanto las agregaciones como una copia de los datos del origen (normalmente del Data Warehouse) en el cubo multidimensional. Se podría parar el Data Warehouse. MOLAP ofrece el mayor rendimiento, pero requiere más espacio de almacenamiento debido a dicha duplicación. Hay latencia cuando se usa el almacenamiento MOLAP porque los datos del cubo se actualizan solo cuando se procesa el cubo, por lo que los cambios desde el origen de datos solo se actualizan periódicamente. Podemos usar el almacenamiento en caché proactivo con MOLAP. Podemos utilizar un almacenamiento en caché proactivo, que notifica al servidor cuando se realizan cambios en la fuente de datos y que luego se incorporan. Mientras la caché se reconstruye con nuevos datos, podríamos optar por enviar consultas a los datos por ROLAP, que están actualizados, pero son más lentos o bien al almacenamiento MOLAP original, que es más rápido, pero no tendríamos los nuevos datos hasta que se procesase de nuevo.
Normalmente, las actualizaciones serían diarias. Lo normal es programar la incorporación de nuevos datos en el Data Wharehouse por la noche y justo después procesar el cubo MOLAP. Sin embargo, algunos sistemas están en uso las 24/7. Para obtener el máximo rendimiento. Cuando se actualizan los objetos, se requerirá algún tiempo de inactividad. Esto se podría procesando el cubo en un servidor intermedio y utilizando la sincronización de la base de datos para copiar los datos procesados en el servidor de producción.
HOLAP (Hybrid Online Analytical Processing). Este almacenamiento es un híbrido entre el MOLAP y el ROLAP. En este modo almacena las agregaciones en el cubo multidimensional y deja los datos de origen en la base de datos relacional. Esta puede ser una buena solución cuando rara vez se accede a los datos. Si se accede con frecuencia a los datos, MOLAP proporcionaría un rendimiento mejorado.
Nota: Hay que considerar el almacenamiento del modelo tabular como una alternativa a ROLAP y HOLAP.
Como conclusión, el modelo óptimo para montar un cubo multidimensional sería siempre MOLAP. En cualquier otro caso, ir a un modelo tabular en lugar de ROLAP o HOLAP, sobre todo si luego las aplicaciones finales estarán desarrolladas con Power BI.
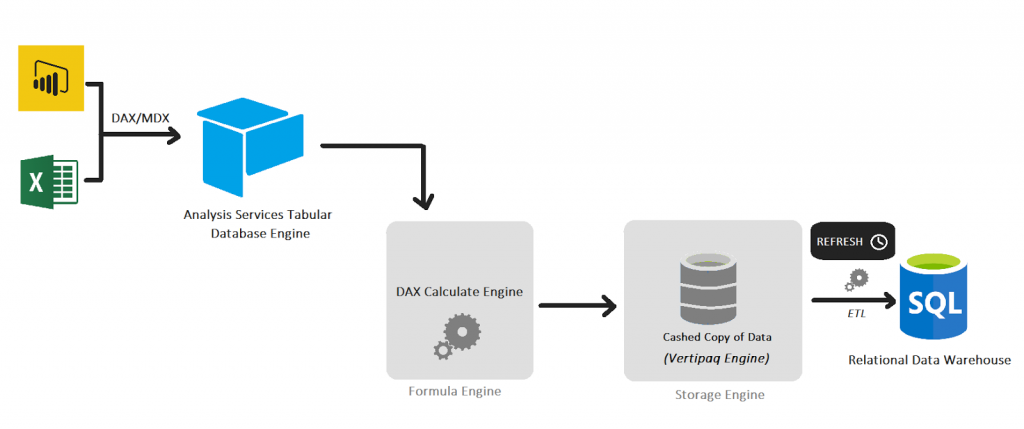
Modelo TABULAR. Este modelo se basa en bases de datos in-memory (en memoria) que utilizan el motor analítico de proceso y almacenamiento xVelocity (inicialmente denominado VertiPaq). Este motor utiliza un almacenamiento basado en columnas ysofisticados algoritmos de compresión para ofrecernos tiempos de consulta muy rápidos, incluso con grandes volúmenes de datos. El modelo tabular, muestra los datos en formato relacional, es decir, interactuamos con tablas y relaciones en lugar de cubos. Además, podemos decir que el rendimiento de xVelocity puede superar al rendimiento de índices ColumnStore (creados en la estructura de las tablas de la base de datos) lógicamente al tratarse de un modelo en memoria. La arquitectura ideal para un rendimiento ultra rápido, sería poder disponer de ColumnStore en la BDs y .
Los modelos tabulares son adecuados tanto para aplicaciones personales como para soluciones departamentales con grandes volúmenes de datos.
Las principales ventajas entre el modelo tabular y el modelo multidimensional son:
- El modelo relacional sobre el que se diseña el modelo tabular es ampliamente comprendido e intuitivo por lo que la barrera de aprendizaje es mucho más rápida para los desarrolladores. De esta forma, los costes de proyecto son menores.
- El diseño de los modelos tabulares generalmente es más simple que los modelos multidimensionales, por lo que el tiempo de implementación de los proyectos es más rápido.
- El modelo tabular utiliza el lenguaje DAX al igual que Power BI y los modelos multidimensionales MDX.
- Caracterísitcas de rendimiento:
- Modelo Tabular:
- + memoria y – disco
- Muchos más Data Sources que el modelo multidimensional
- Tendencia del mercado
- Modelo Multidimensional:
- + disco y – memoria
- En desuso para proyecto nuevos
- Modelo Tabular:





Muy bien explicado
Se comprende perfectamente, gracias por la explicación.
muy bueno gracias